
An Enhanced MultiModal ReAsoning Benchmark
Can MLLMs Reason in Multimodality?
*Equal contribution
*Equal contribution
🔥 [2025-06-16]: The Leaderboard has been updated with the results of SRPO (7B and 32B) and Skywork-R1V2-38B. We welcome more reasoning-focused MLLMs to join the challenge!
🎉 [2025-06-08]: Our paper has been accepted for Oral (Top 1%🔥) on ICML 2025! See you in Vancouver!!
🪧 [2025-05-31]: EMMA is supported in VLMEvalKit now!
🎉 [2025-05-01]: Our paper has been accepted for Spotlight (Top2.6%) on ICML 2025!
🔥 [2025-04-30]: The Leaderboard has been updated. Currently, Gemini-2.5-pro-exp-03-25🥇, o4-mini🥈, and o3🥉 on EMMA-Mini. And VL-Rethinker-72B ranks first in open source models. The case-by-case comparison between Human Sketch and Model Response has also been added.
🔥 [2025-03-02]: Exciting updates on the Leaderboard! We've added claude-3-7-sonnet-20250219 and kimi-k1.5-Preview performances. Currently, claude-3-7-sonnet-20250219🥇, Gemini-2.0-Flash-Thinking-exp-0121🥈, and o1🥉 on EMMA-Mini.
🔥 [2025-01-28]: We've added Gemini-2.0-Flash-Thinking-0121 and QVQ-72B-Preview performances on the Leaderboard!
🚀 [2025-01-09]: We released EMMA, a benchmark for advanced multimodal reasoning. 🥳The ability to organically reason over and with both text and images is a pillar of human intelligence, yet the ability of Multimodal Large Language Models (MLLMs) to perform such multimodal reasoning remains under-explored. Existing benchmarks often emphasize text-dominant reasoning or rely on shallow visual cues, failing to adequately assess integrated visual and textual reasoning.
We introduce , a benchmark targeting organic multimodal reasoning across mathematics, physics, chemistry, and coding. EMMA tasks demand advanced cross-modal reasoning that cannot be addressed by reasoning independently in each modality, offering an enhanced test suite for MLLMs' reasoning capabilities.
Our evaluation of state-of-the-art MLLMs on EMMA reveals significant limitations in handling complex multimodal and multi-step reasoning tasks, with even advanced techniques like Chain-of-Thought prompting and test-time compute scaling underperforming. These findings underscore the need for improved multimodal architectures and training paradigms to close the gap between human and model reasoning in multimodality.
| Reset | EMMA | EMMA-Mini | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Name | Size | CoT prompting | Overall | Math | Physics | Chemistry | Coding | Overall | Math | Physics | Chemistry | Coding |
Overall results of different models on the EMMA leaderboard. The best-performing model in each category is in-bold, and the second best is underlined.*: results provided by the authors.
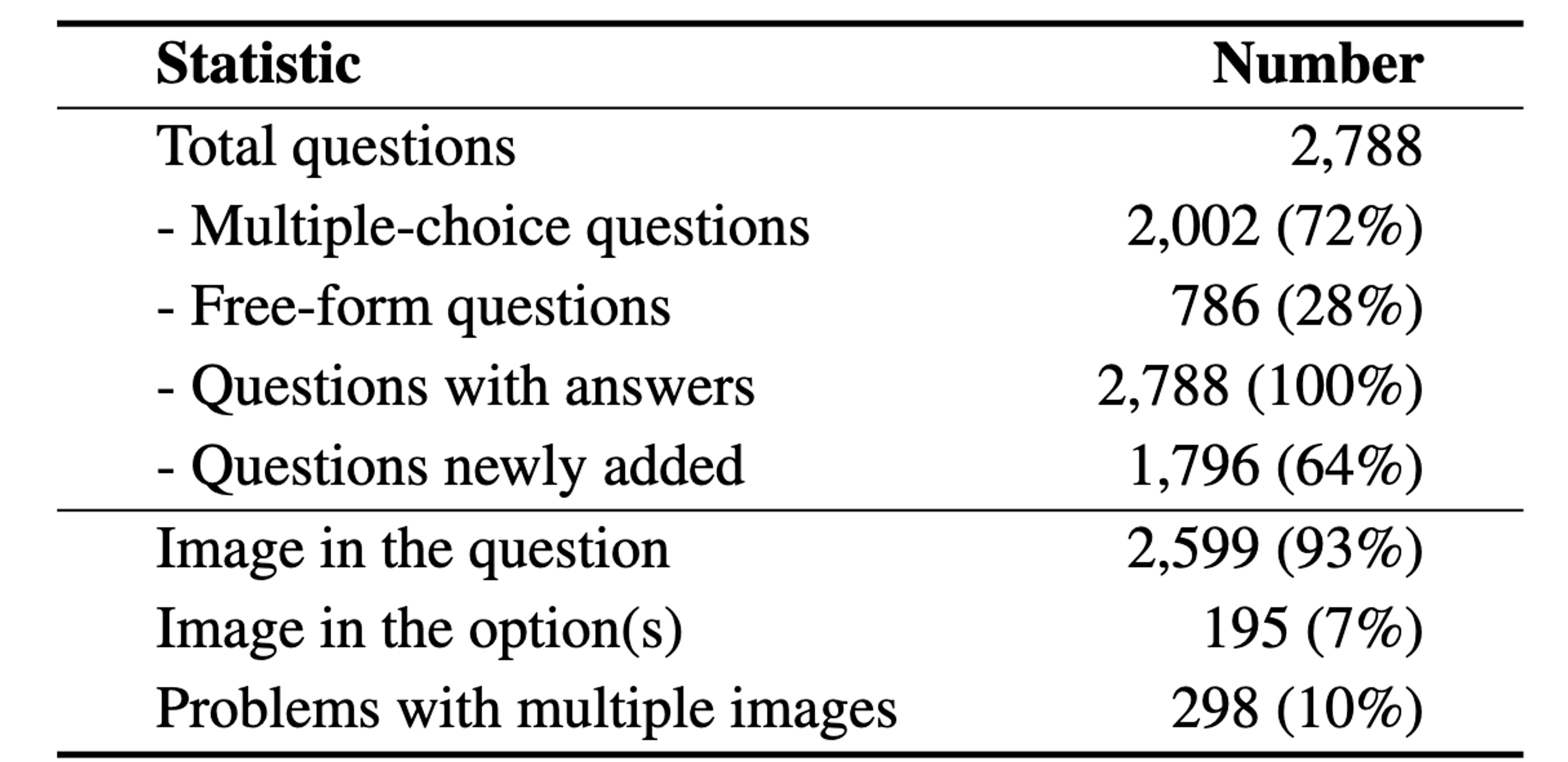
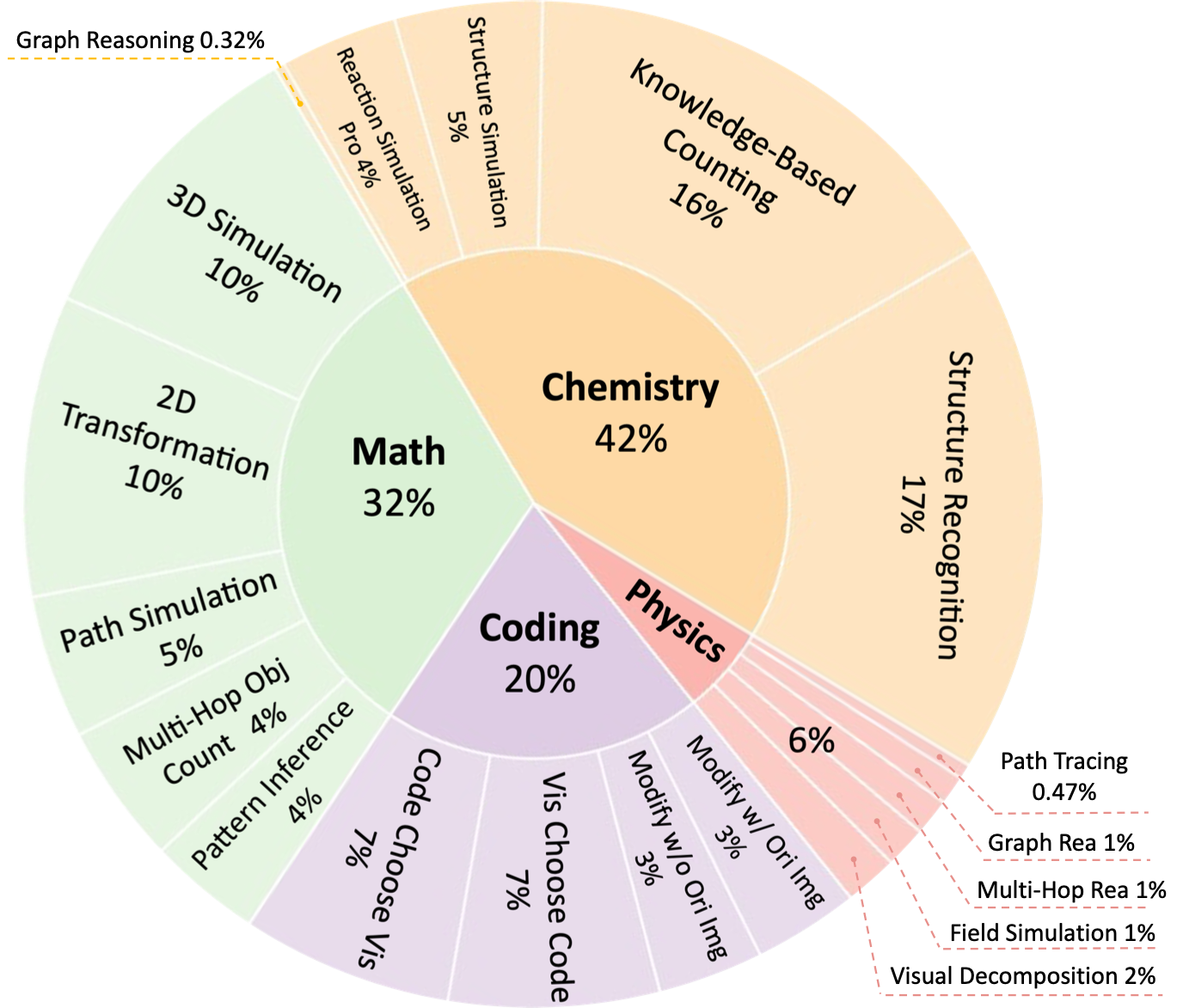
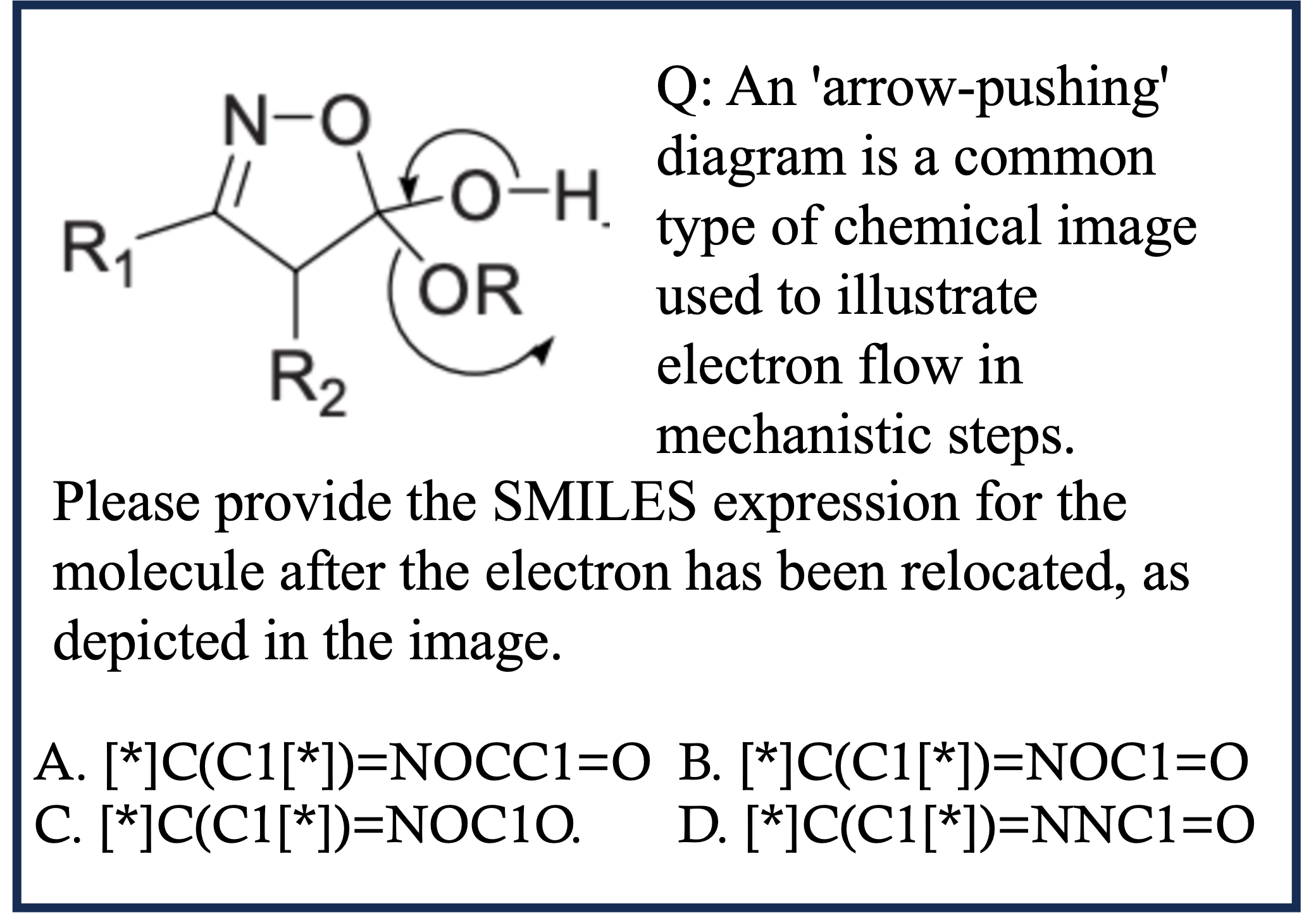
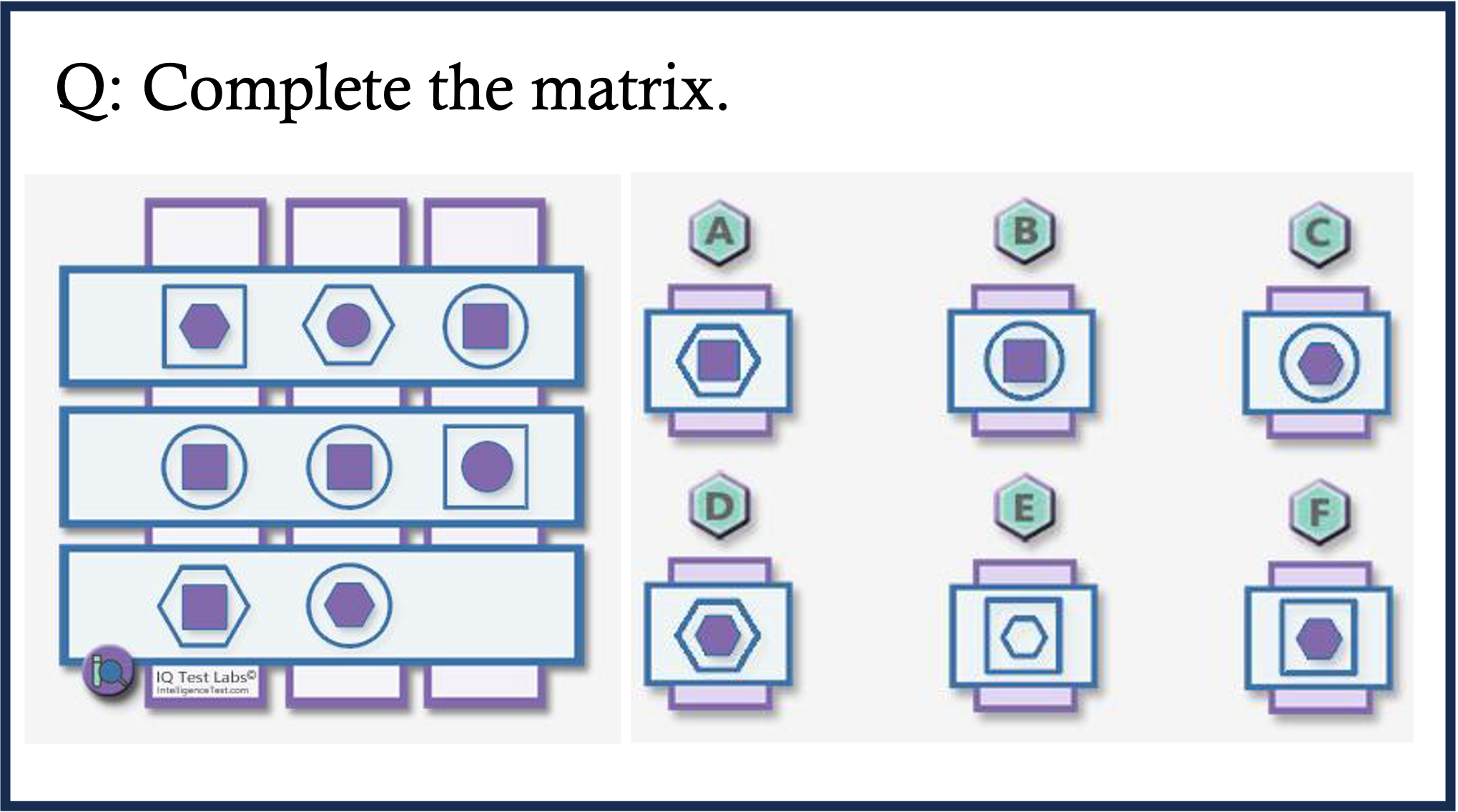
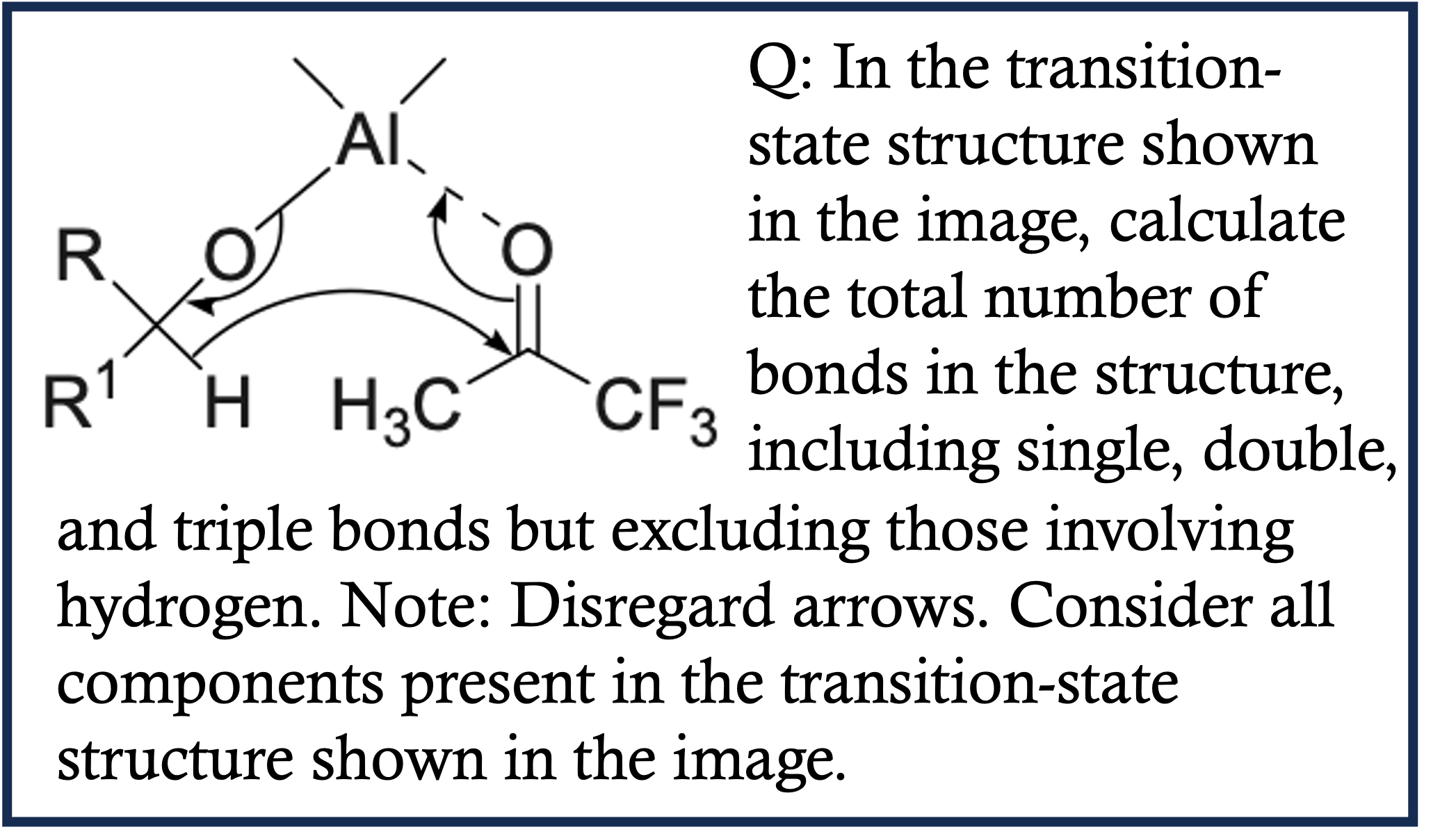
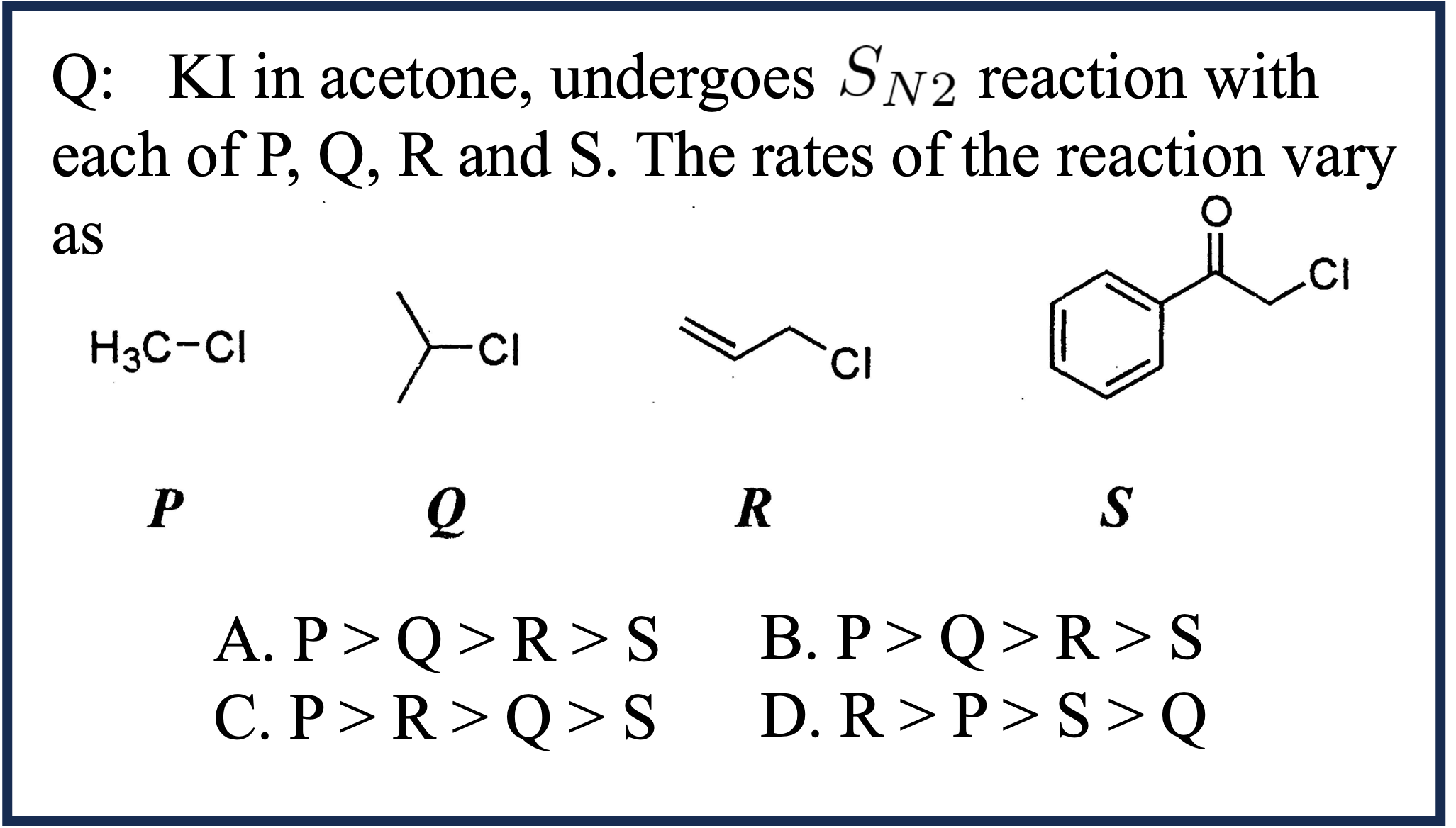
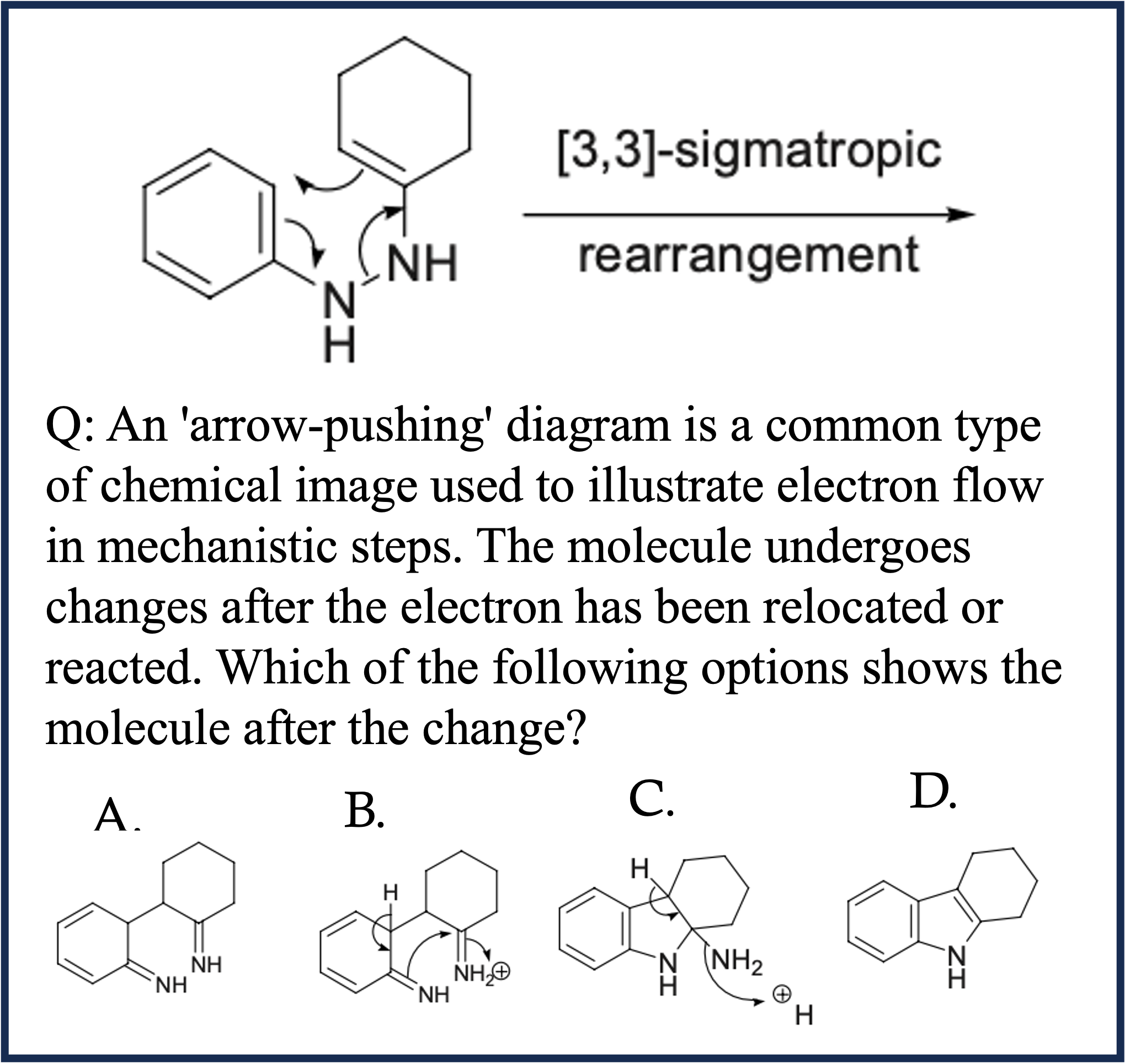
EMMA is composed of 2,788 problems , of which 1,796 are newly constructed , across four domains: math, physics, chemistry, and coding. To provide fine-grained insights into how MLLMs might fail in multimodal reasoning, we assign labels to each problem in our benchmark. These labels are either created by domain experts or assigned by GPT-4o and subsequently verified by experts. As shown in Category Figure, questions in EMMA assess a wide array of multimodal reasoning skills. For example, the pattern inference problem in math challenges models to identify and generalize visual patterns; the visual decomposition simulation problem in physics requires graphically decomposing forces to determine resultant effects; the reaction simulation problem in chemistry demands precise interpretation and simulation of electron movement; the 3D visualization problem in coding.
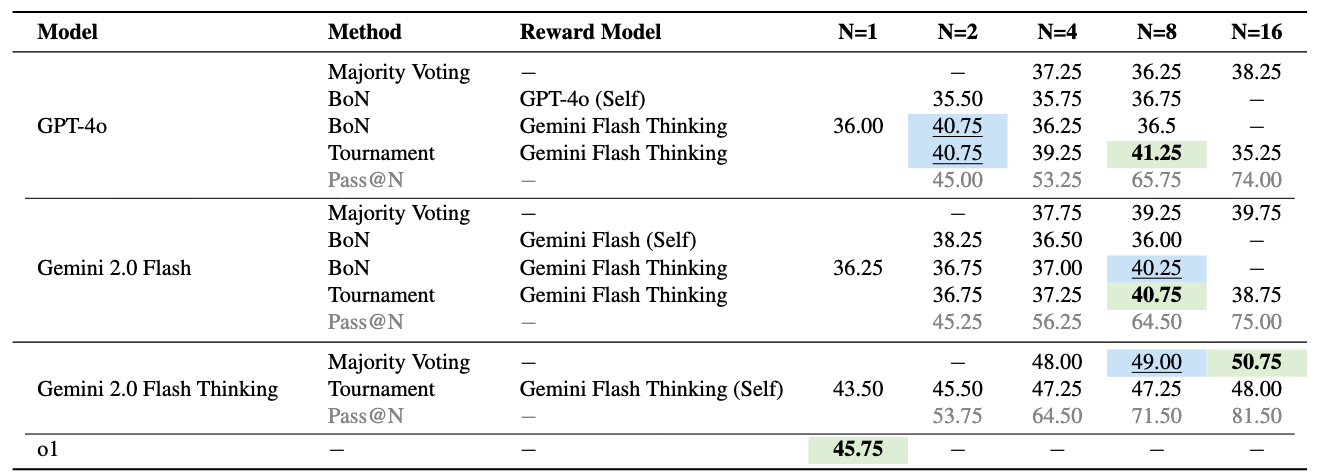
We also try various test-time compute scaling strategies. While they tend to boost model performance, they are far from enough to close the gap to human-level performance. The best model and scaling strategy configuration we try still trails humans by 27%.
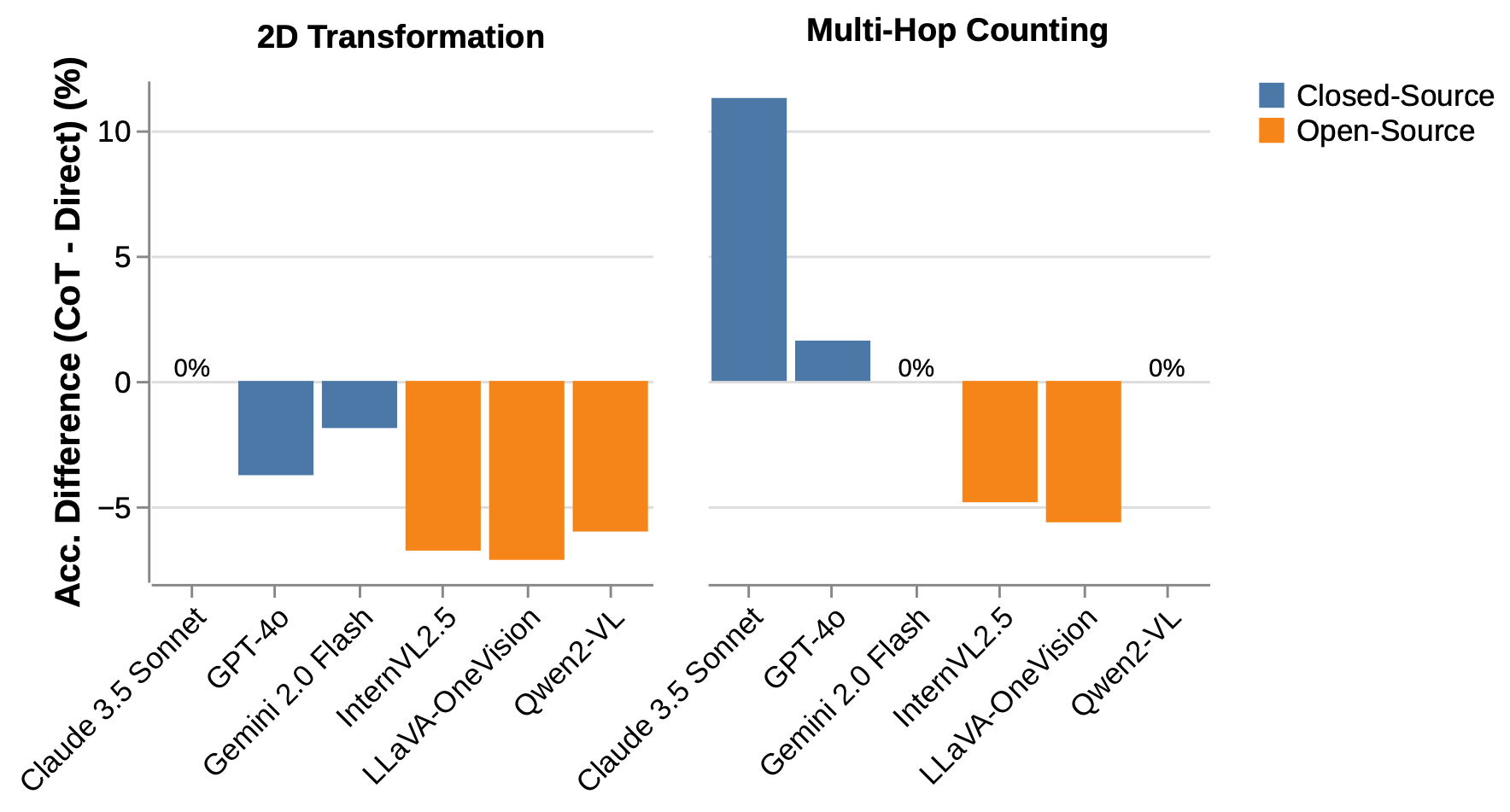
Using the abels for each question based on the multimodal skills it assesses, we find that CoT prompting hurts performance on visual-reasoning-heavy tasks, while it benefits closed-source models on tasks where textual CoT is theoretically useful.
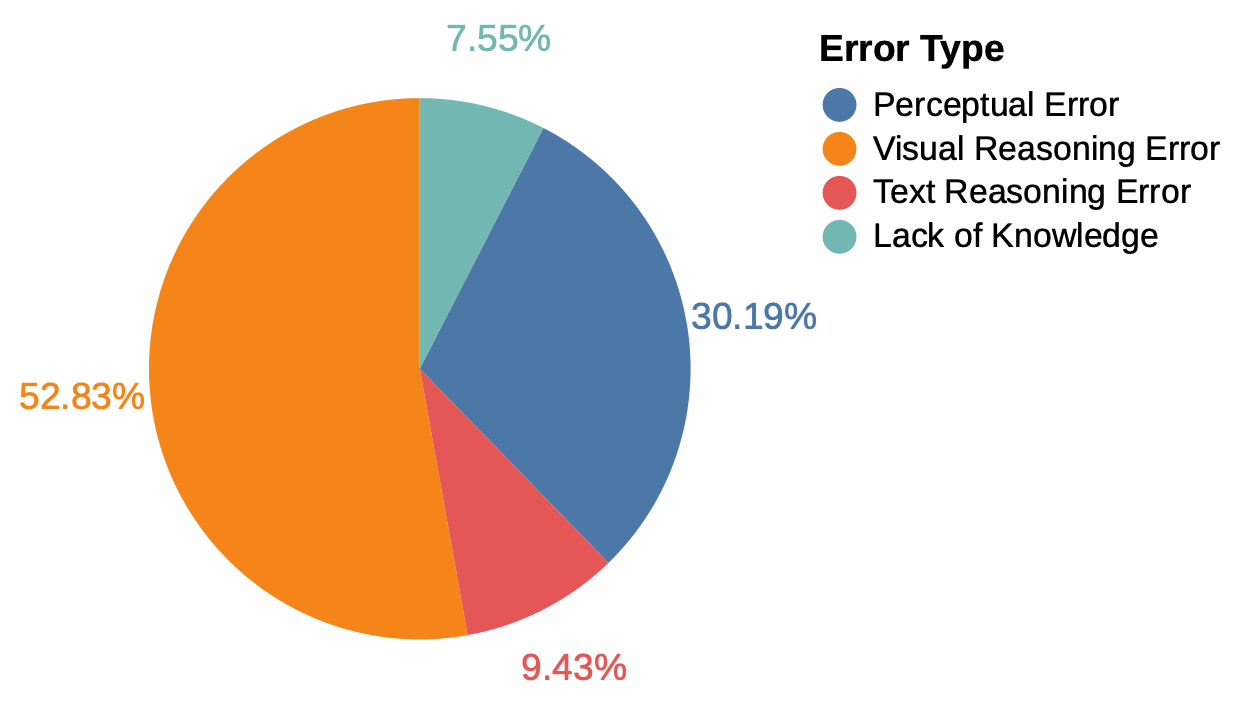
Distribution of error types made by o1 on the math and coding portions of EMMA-mini. The majority of errors arise in visual reasoning.

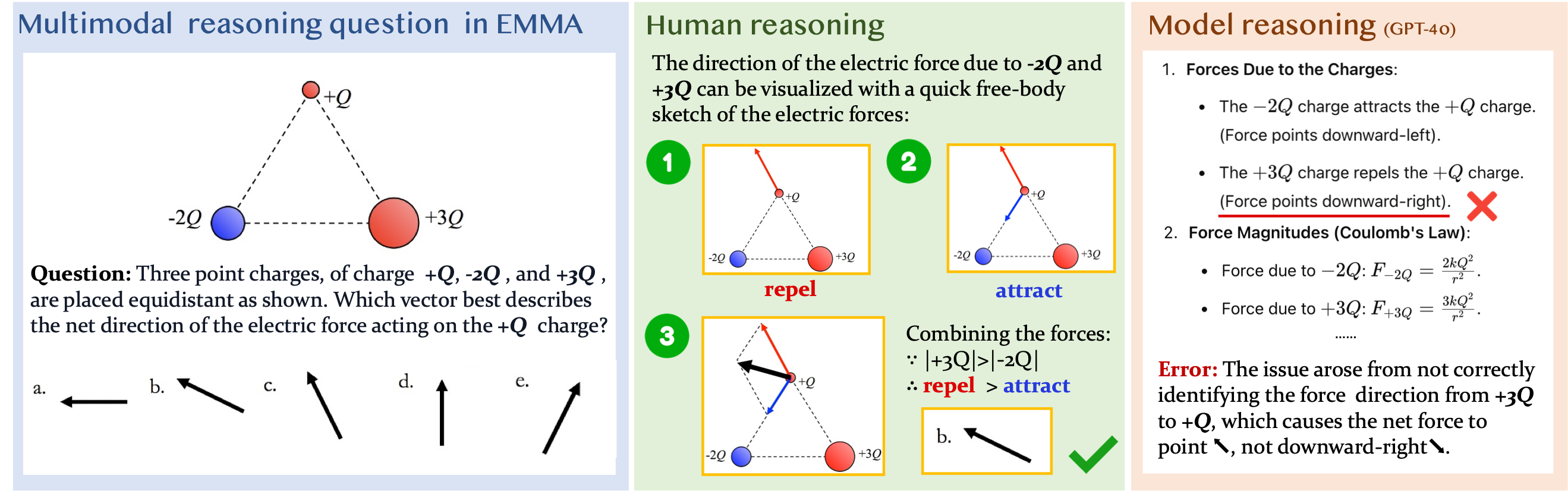
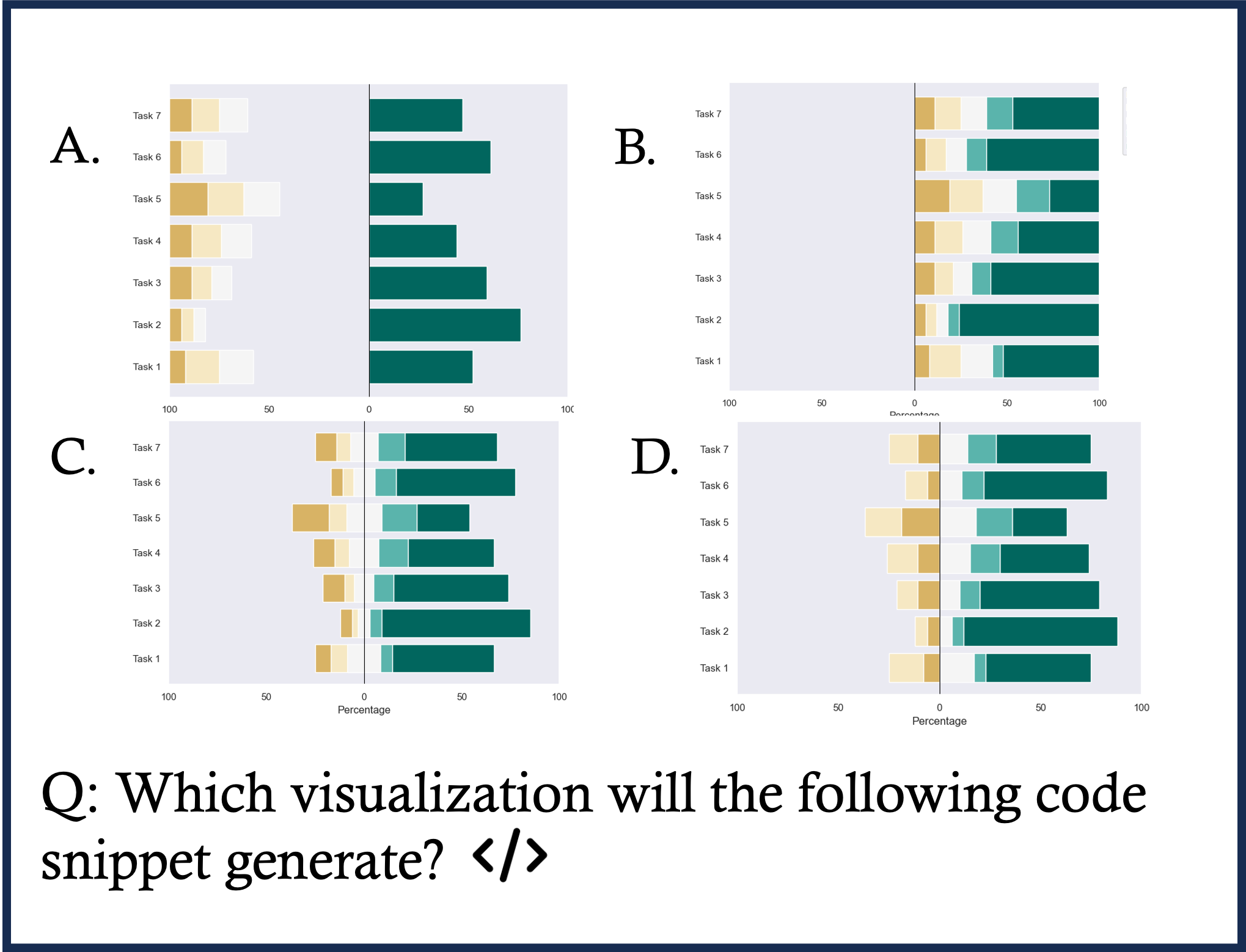
Math Case 1

Math Case 2

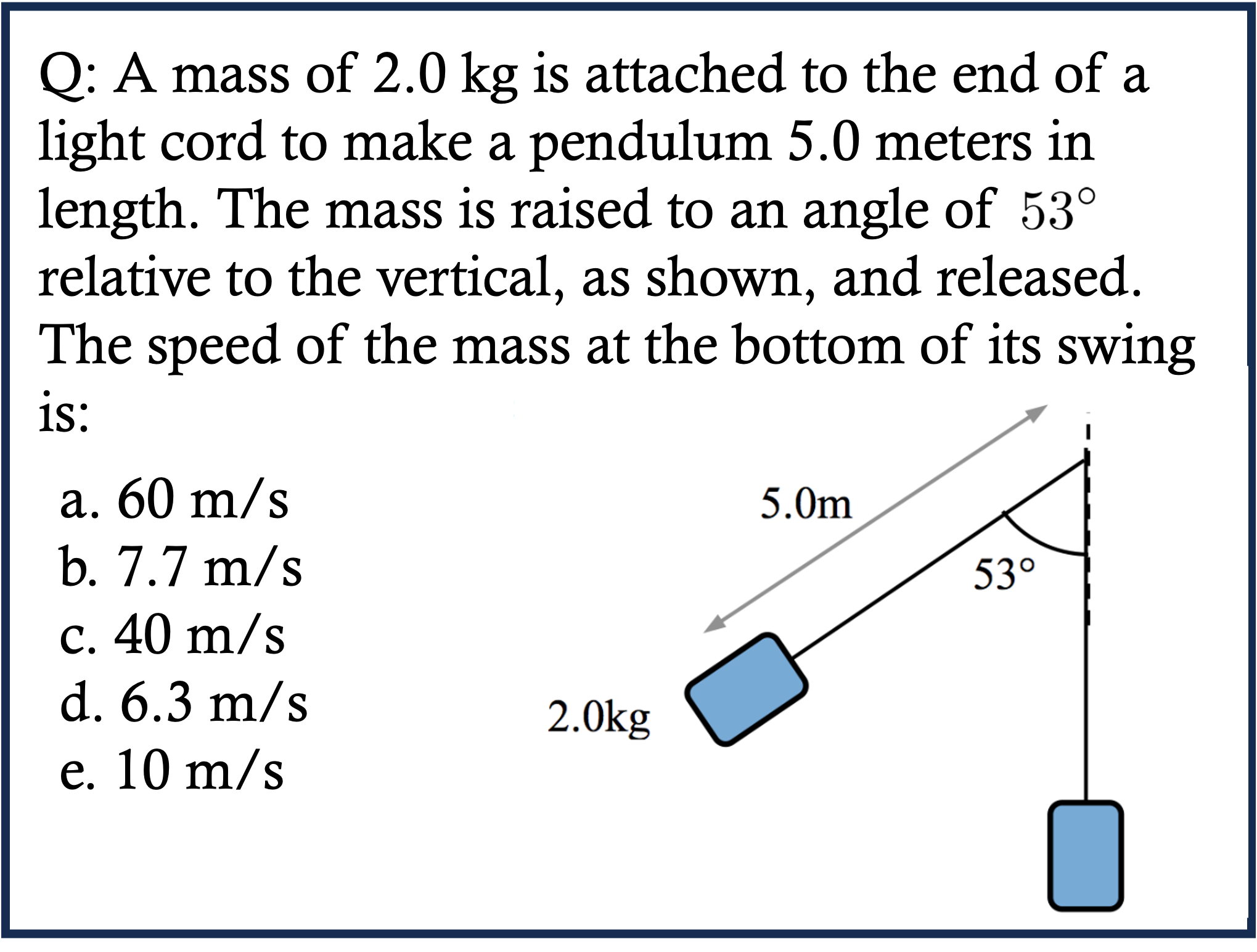
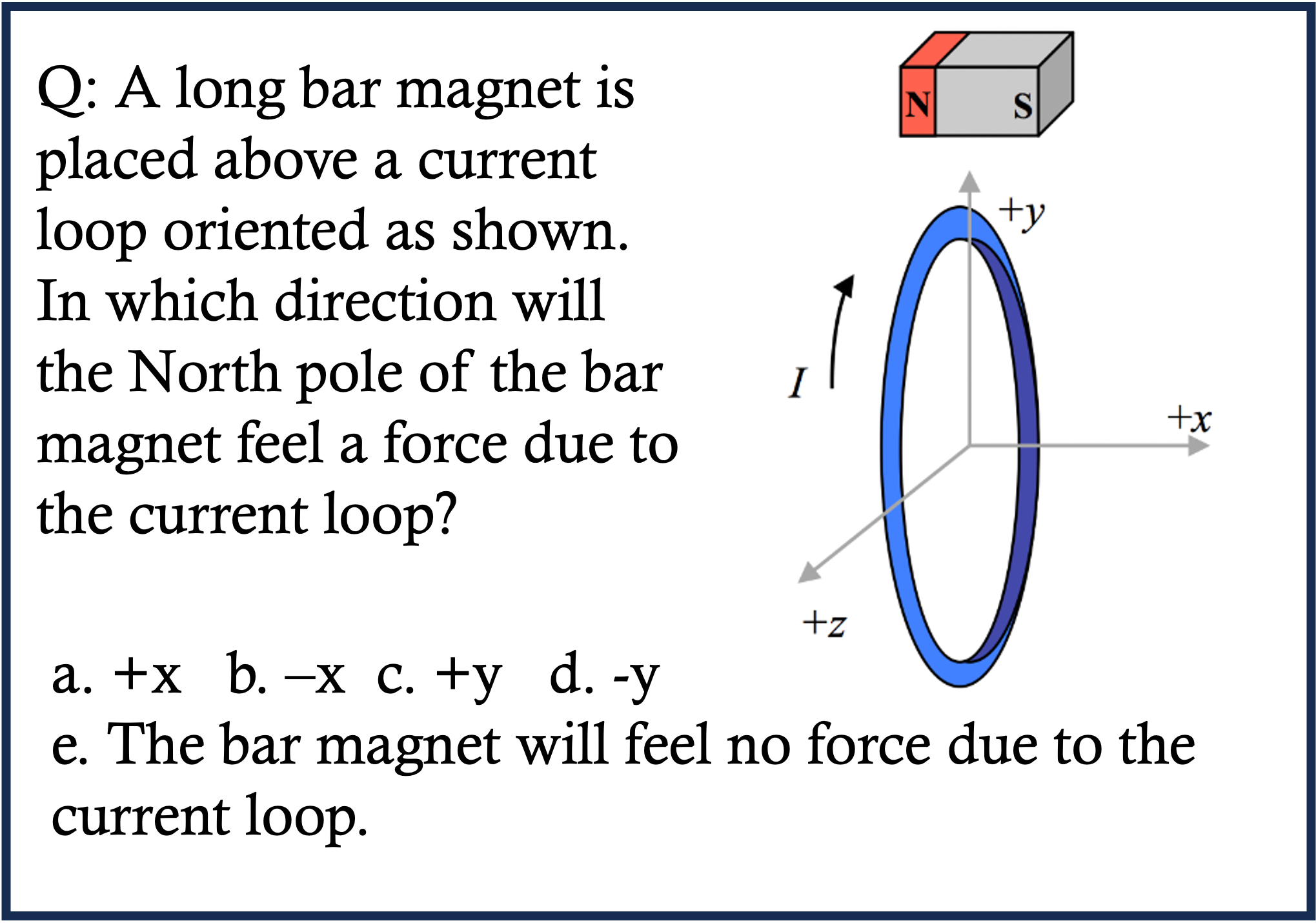
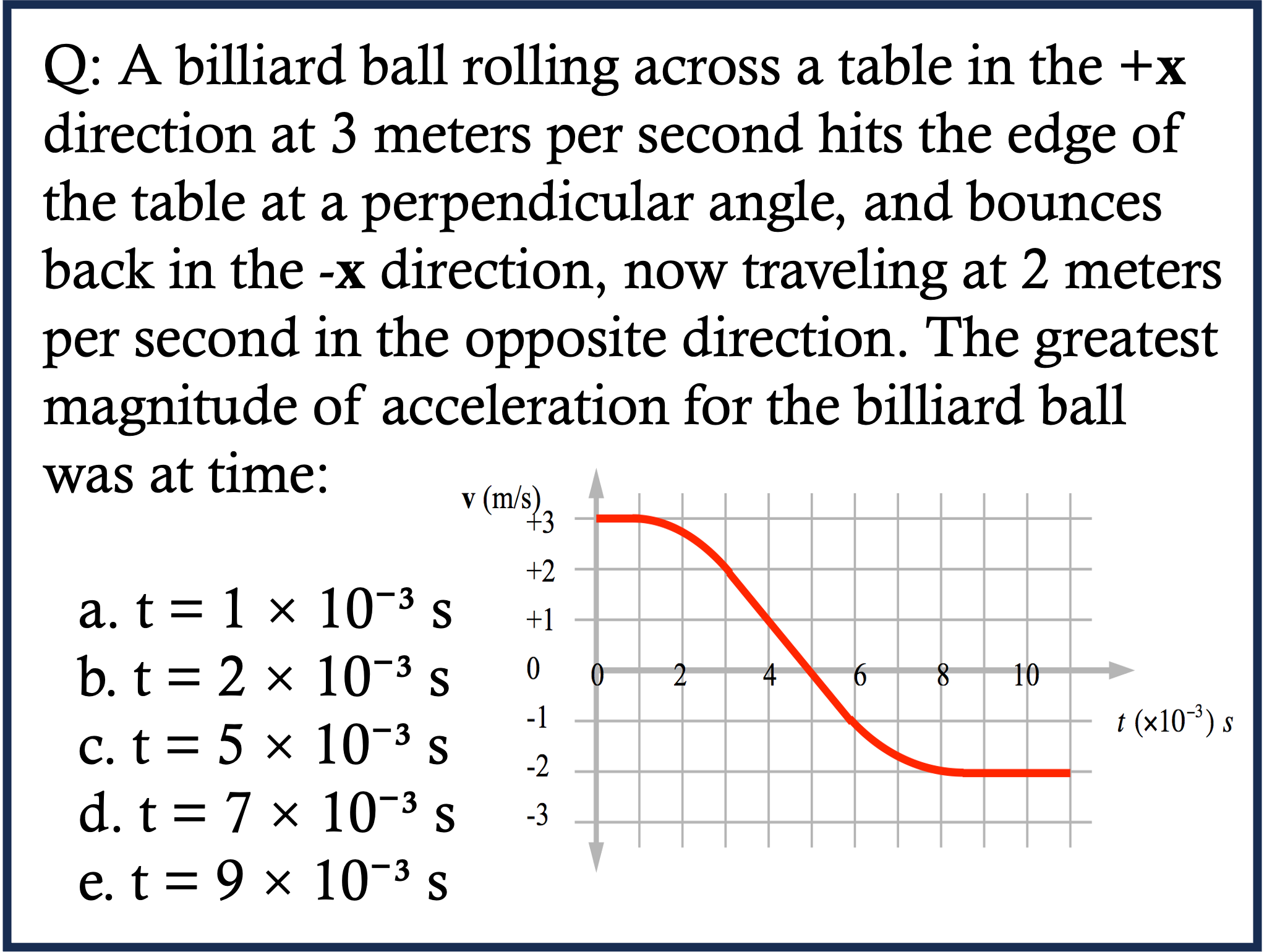
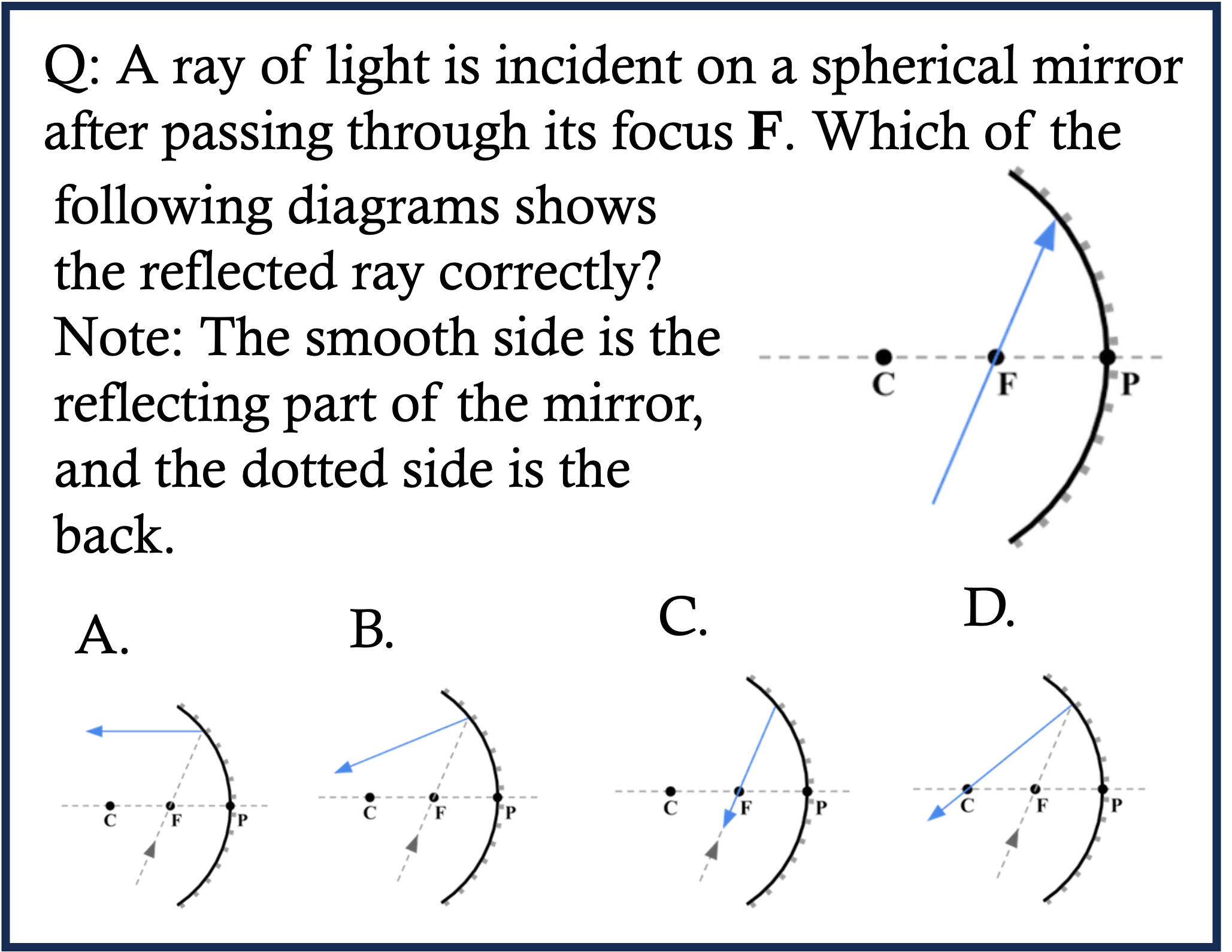
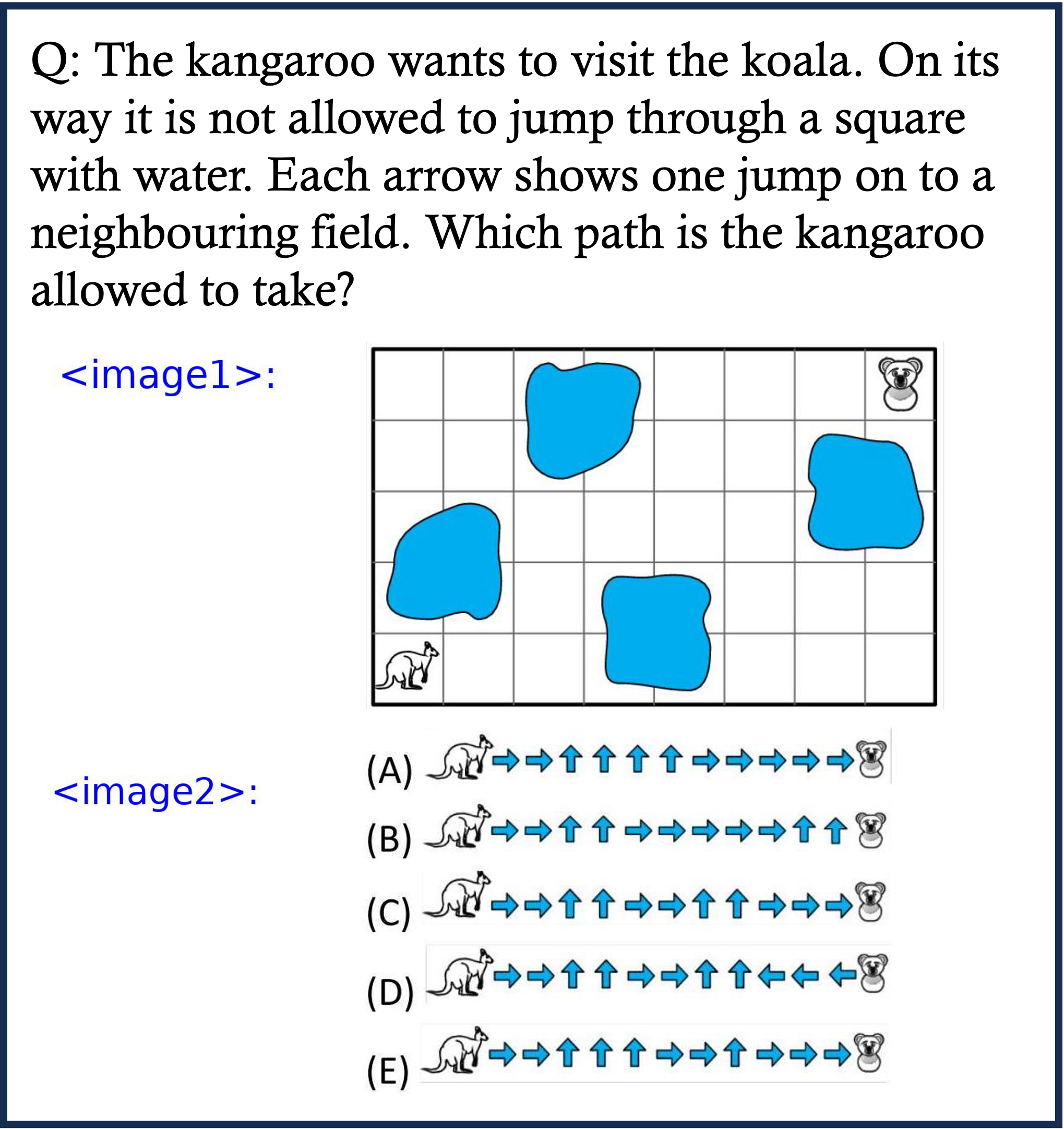
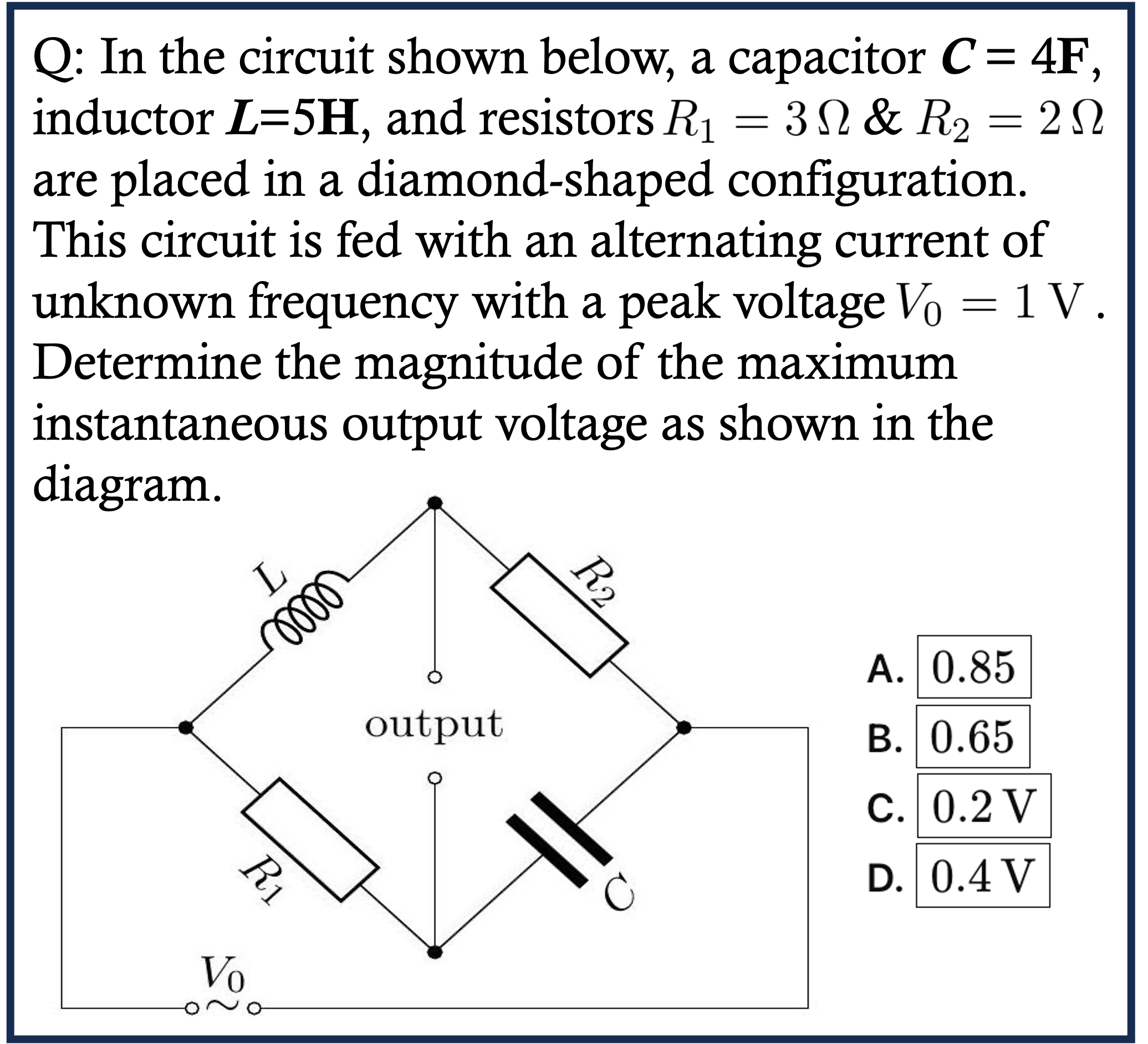
Physics Case 1

Physics Case 2

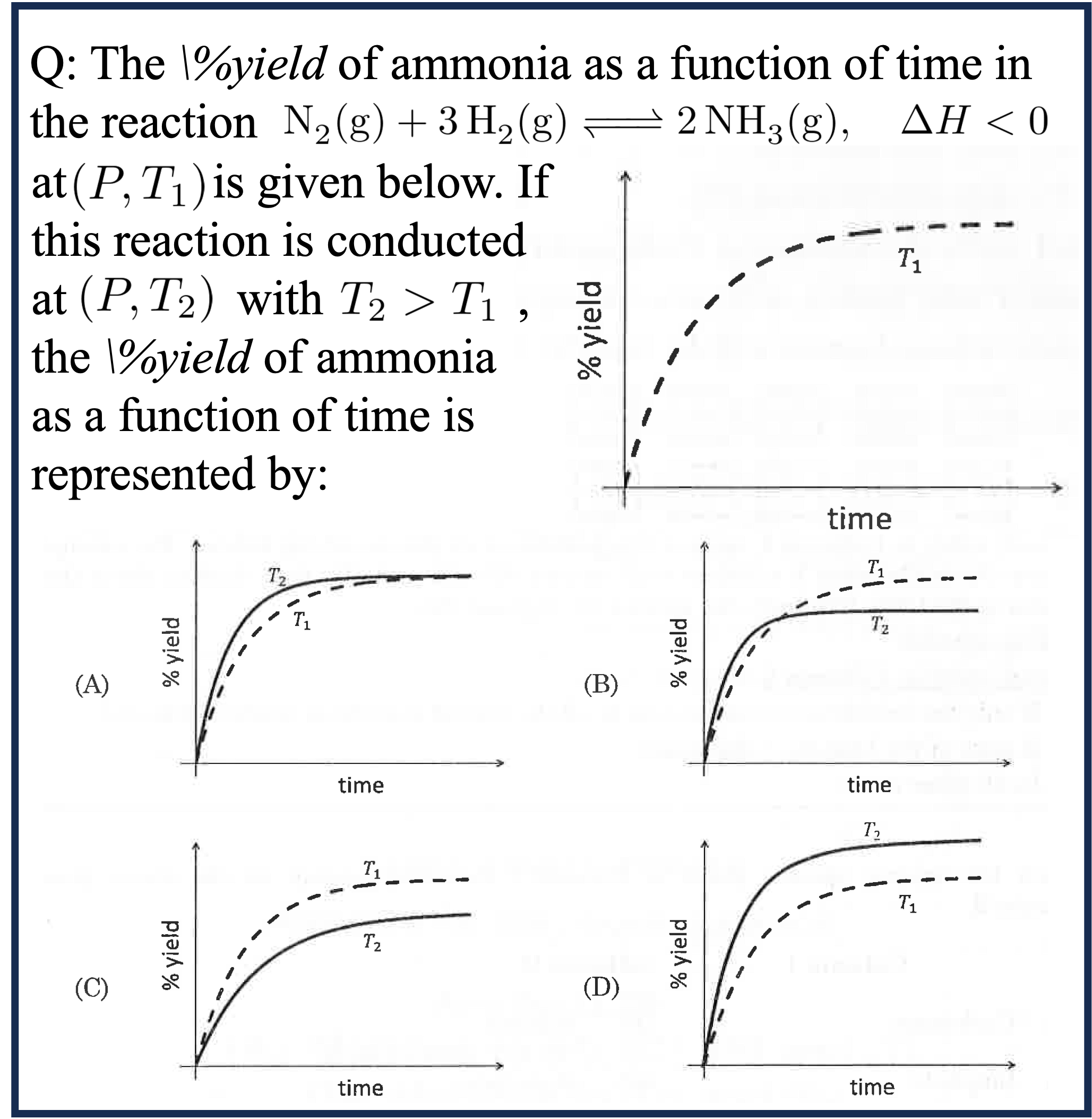
Chemistry Case 1

Physics Case 3
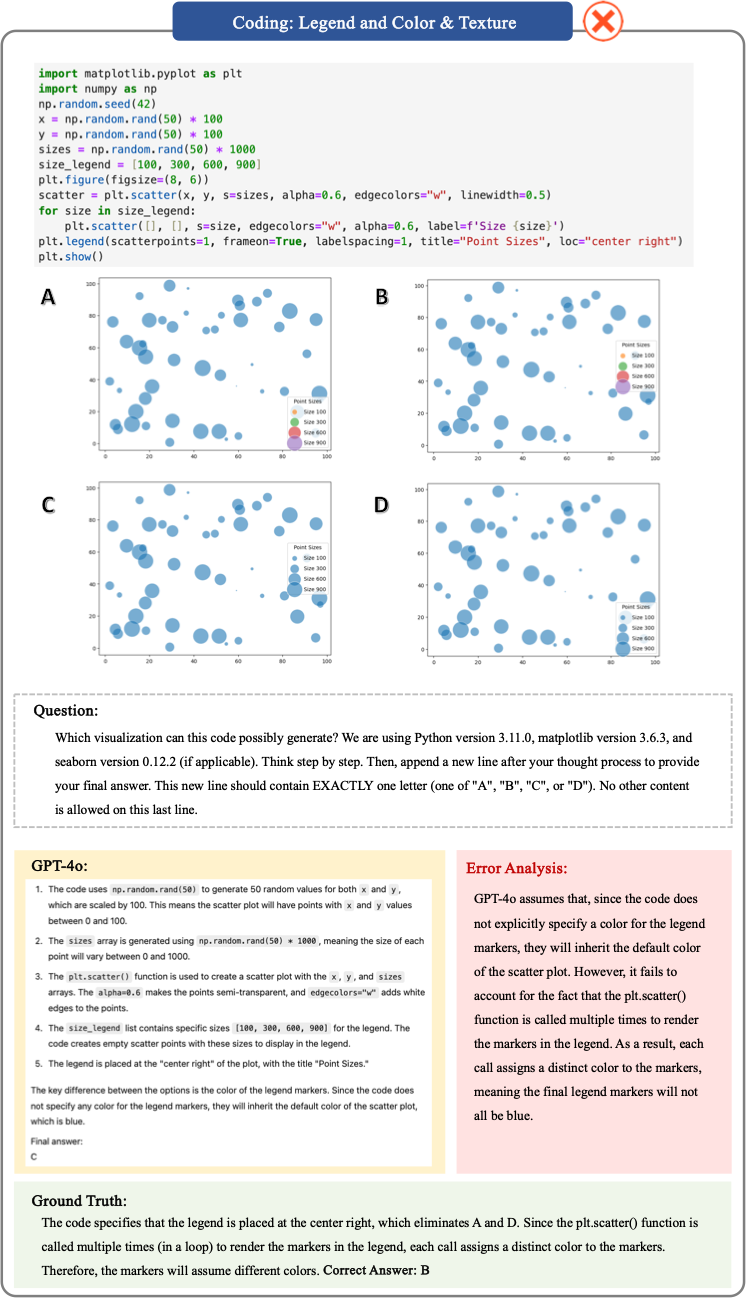
Coding Case 1

Coding Case 2
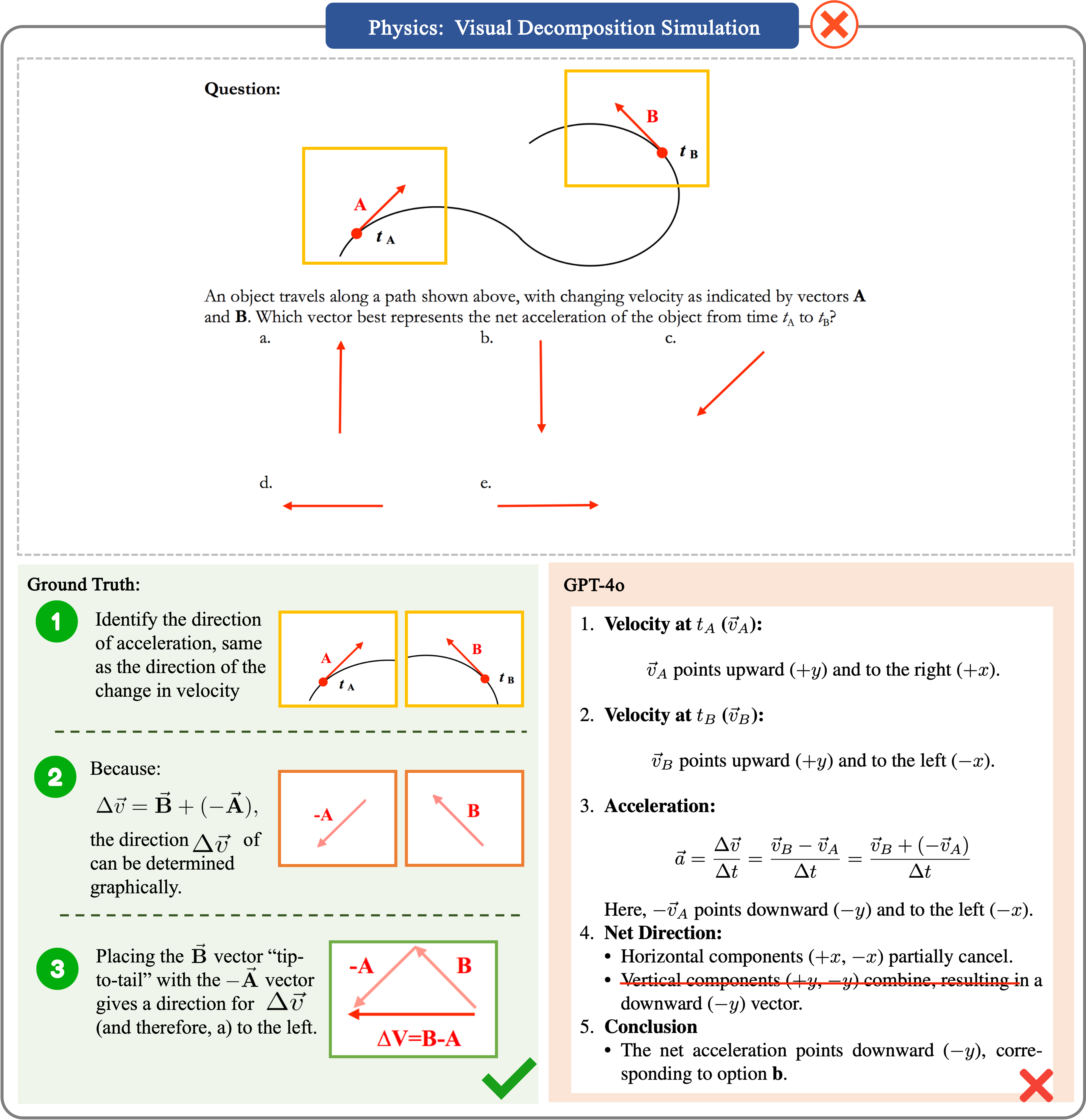
Physics Case 4

Physics Case 5

Physics Case 6
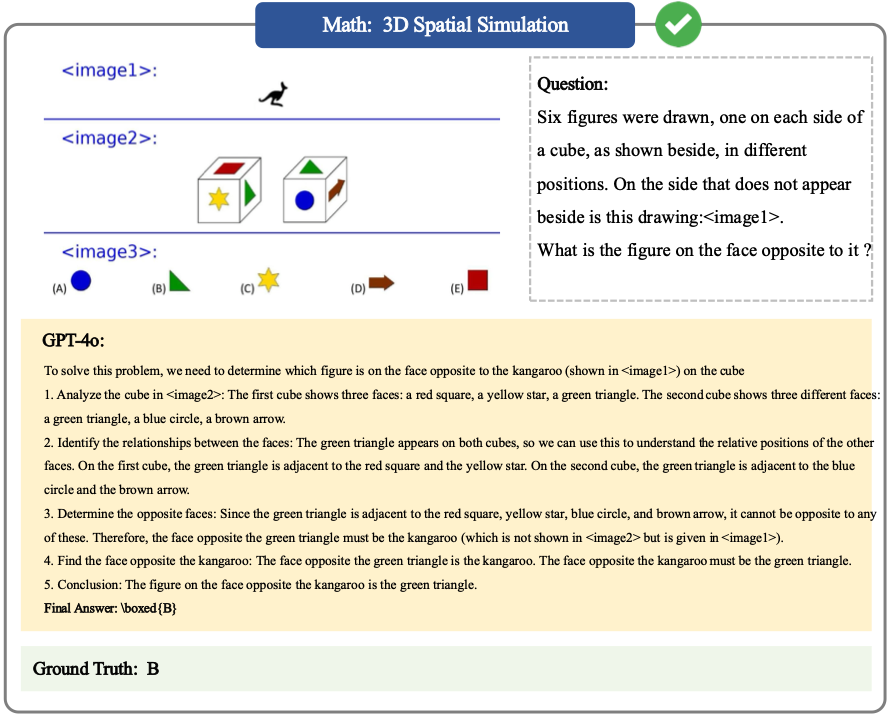
Math Case 3
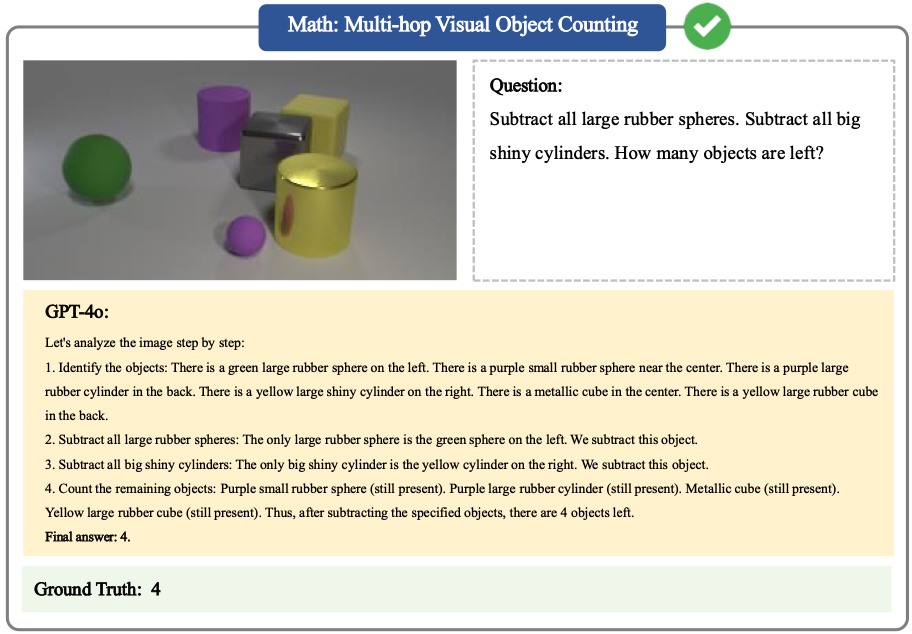
Math Case 4
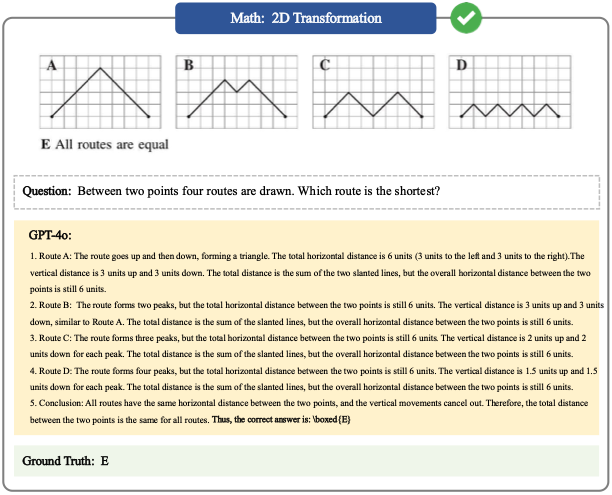
Math Case 5

Math Case 6

Math Case 7
More examples detailed in the paper.
Human sketch
Click on the image to display the answer. Please check complete Coding questions here.


@article{hao2025can,
title={Can MLLMs Reason in Multimodality? EMMA: An Enhanced MultiModal ReAsoning Benchmark},
author={Hao, Yunzhuo and Gu, Jiawei and Wang, Huichen Will and Li, Linjie and Yang, Zhengyuan and Wang, Lijuan and Cheng, Yu},
journal={arXiv preprint arXiv:2501.05444},
year={2025}
}